
By now, if your organisation has anything to do with building or running any kind of service on the Internet, you’ve probably started hearing about Docker, and perhaps even the term “containerisation” (of which Docker is the most popular implementation). So, what is it, and why are people so excited about it?
I won’t go into the deep technical details of what containerisation is in this article, but at a high level you can think of it as a kind of super-lightweight virtualisation technology. Containers require a fraction of the startup-time, memory, CPU and storage overheads of traditional virtual machines (VMs), and are designed from the ground up with automation in mind
This orders-of-magnitude difference in overheads allows for devops-aligned build, test and deployment workflows which, while technically possible with VMs, haven’t been especially practical until the advent of containerisation. In the devops/virtualisation/cloud “pets or cattle†metaphor, containerisation means that when you’re designing and building your farm, you can summon an entire herd of cattle (or chickens, if you prefer) in moments to test any aspect of the design, and have them vanish again as soon as they’re not needed.
So how does a containerised approach affect the delivery of applications through to production environments? Consider the following diagram of the build, deployment and maintenance processes for an application consisting of an app server and a DBMS running on VMs:
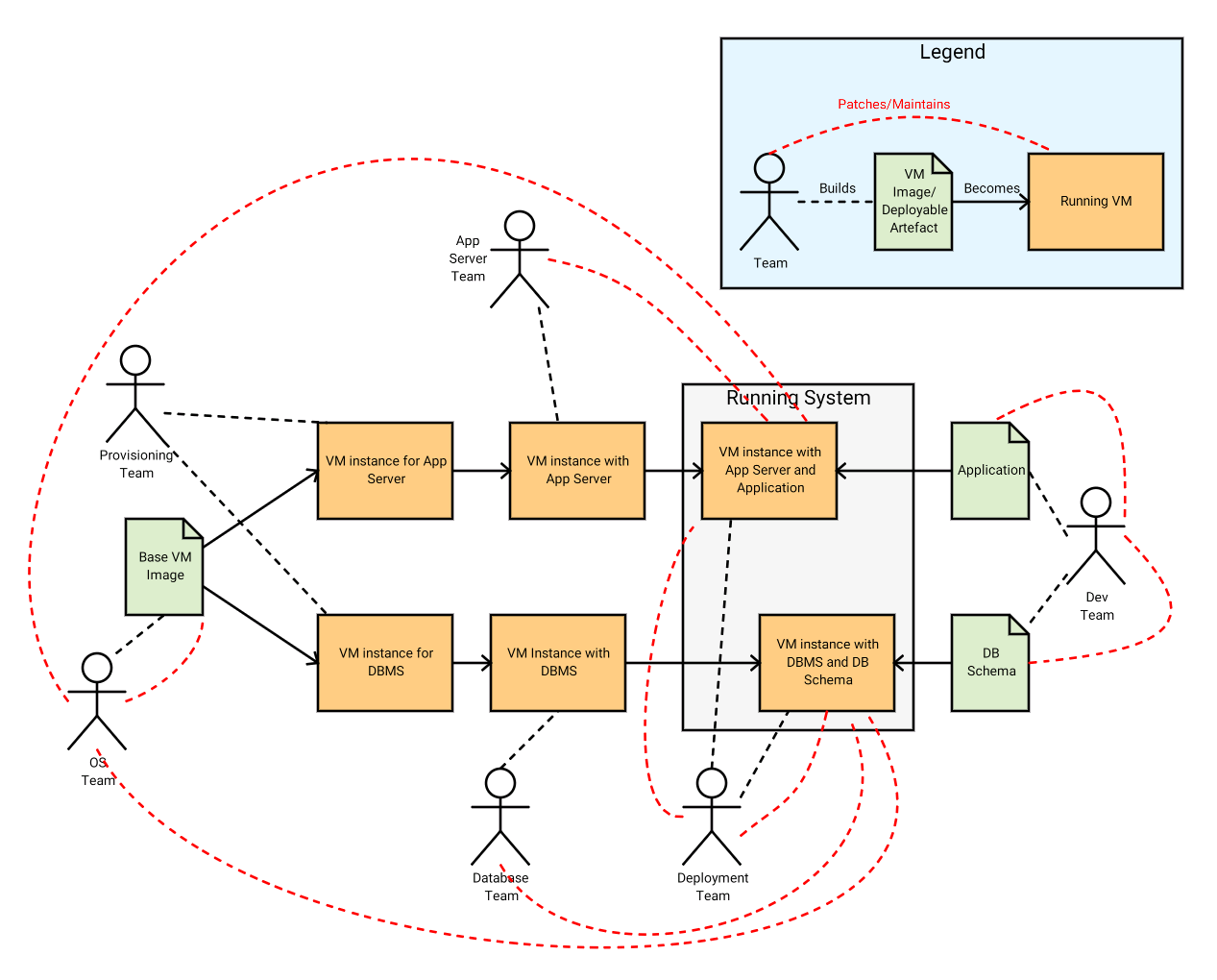
This isn’t supposed to accurately capture a specific, real-world arrangement of teams, and I’m ignoring non-production environments, but it gives you the general flavour of how this kind of structure often works. So, what are we looking at?
At the left edge you have your OS team creating the base operating system-VM that everything else is based on. In an ideal world this is a scripted process so that when the next OS revision is released or some core configuration of the build is changed, every other aspect of the VM can be rebuilt identically. Often though, it’s a manual process, and patches are applied on top of patches on top of the base image, rather than rebuilding from scratch each time.
Next, when a new application requires some prod servers, they are provisioned by deploying the base OS image to some VM hosting infrastructure – every change from here on occurs cumulatively to a running system. Once the base VMs are running, the database and application server teams install their respective platforms. This, too, would ideally be a fully scripted process, but is often not.
Coming in from the right side of the diagram, your dev team is building the application itself, and the DB schema it uses. For a range of reasons, the app server, DBMS and base OS they use in their non-production environments (not pictured) are often very different from the ones they will encounter in prod. This could be as minor as different patch-levels and small configuration differences, or as major as a totally different app server.
At-last, the deployment team unites the dev team’s artefacts with the running VMs to create the running system (again, ideally automated, but often not). But this is by no means the end – all the red dashed lines in the diagram indicate patches and maintenance that might occur after the application goes live. Note that almost every team has a hand in changing the system that’s running in production. Their changes are layered on top of one another in the order they occur, and aren’t necessarily reflected in the non-prod environments. Soon it becomes impossible to characterise the exact state of the system, to quickly add or replace servers, or replicate it in non-prod environments.
Now take a look at this diagram of the same system running on containers, rather than VMs:

I’ve left the team labels the same for clarity in the diagram above and discussion below, but containerisation lends itself much more to a devops-based approach which allows for a less siloed model.
Here, rather than working with and gradually patching running systems, most teams work with system images, and the scripts necessary to build them. Automation of tasks like installing the base OS, app server and DBMS are no-longer nice-to-haves, but core requirements of the system. The ultra-low overheads of containers compared to VMs contribute a lot here – when you’re debugging a script that installs a DBMS, it helps if you can spin up the machine it runs on in a few seconds rather than several minutes for each trial run.
Notice that the dev team no-longer works on two separate artefacts independent of the platforms they will eventually be deployed to. Instead, they work with the exact DBMS and app server systems with the exact same configurations, running on the exact same OS images that will be used in prod. Also, they don’t work on them in isolation from one another, they work on the complete system including app server and DBMS, configured to communicate with one-another exactly the same way they will in prod. Deployment is simplified to a single process, rather than parallel tasks for application and DBMS schema – there is now no possibility of drift between the configurations of each part of the system.
Rather than having teams patch the running system, patches flow through the delivery workflow – once the OS team releases a new version of the base image, the app server and database teams rebuild their images and ensure they still pass all tests, then the dev team rebuild their images and ensure they pass all tests, then the updated images can be released to production. This would be unreasonably slow for a VM based workflow, particularly for critical patches, but can be completed in as little as minutes or hours with containers.
Perhaps most importantly, once the system is running, there is no maintenance to the running instances of the images. The running containers are immutable – no persistent changes are ever made to them, so you always know their exact configuration, as it’s not possible for anyone from any other team to have modified the system. If a running container ever enters an undefined state through some exotic and rarely-triggered bug, it can be immediately replaced by an identical container, and taken offline for analysis or simply discarded.
This immutability also assists when it comes time to scale your system horizontally. Because you know a new container you spin up will be identical to any already-running containers, and thanks to the inherent automation of every aspect of a containerised system you can spin them up at the click of a button, scaling becomes vastly simpler. Scaling can even be automated, to enable apps to consume more resources across your datacentre as necessary (within reasonable bounds).
So, there’s the basic rundown of how containerisation changes the ways you manage an application’s entire lifecycle, now come the obvious questions:
Q. Isn’t containerisation only for Linux, what about our Windows servers?
A. Containerisation is part of Windows Server 2016. But, and this may be my personal bias creeping in here, when it comes to server platforms, Linux is pretty much where all the innovation is happening, especially in terms of web applications – if you’re going to embrace containerisation, devops, continuous delivery and automation of everything, I recommend looking at Linux first.
Q. What good is a container that starts up instantly if our application server takes five minutes to start, and the application takes another two on top of that?
A. It’s not great. Lifting and shifting your entire existing architecture onto containers is going to deliver some benefits, but it’s when you start moving towards a microservices architecture and leaving behind heavyweight servers and monolithic applications that you can start to realise the full potential of containerisation.
Q. If containers are immutable, how does the database store anything?
A. I’ve glossed over this because it quickly falls into a complex technical discussion that doesn’t add much to the overall picture. In short, each running database container (or any other container requiring persistent storage) has an associated persistent volume, which can be created manually, or dynamically from pools of the appropriate kinds of storage.
Q. Does containerisation make horizontal DB scaling as simple as spinning up new DB containers?
A. No, horizontal DB scaling (while maintaining high availability) is still a complex undertaking, but it pays to look outside the big, traditional RDBMS platforms, and in-particular to the kinds of NoSQL/schemaless DBMS tools that have horizontal scaling as part of their core design. Putting Oracle’s RDBMS inside a container is probably not going to be a winning strategy in your production environment!
Q. With all these containers being spun up all over the place, won’t licensing be a nightmare?
A. Many vendors already allow unlimited non-production instances of their platforms, and others will have to follow if they want to keep up with the modern world. In production you can tailor your container hosts to enable the greatest capacity per license, and develop scaling policies that avoid exceeding the licensed capacity for a given platform. At a higher level, some of these expensively licensed platforms may no longer be particularly necessary or even useful in a containerised, RESTful microservices world where the first reaction to a sick server is to replace it in a few seconds with a brand new one.
Q. Is this all a Trojan Horse to fill our datacentres with unsupported, Open Source software in place of the commercially supported enterprise platforms we have there today?
A. Well…not exactly. The reality is that devops, REST, microservices and containerisation all pave the way for delivery teams to use and self-support the lightweight, customised and, yes, often Open Source solutions that best serve the needs of their particular product, rather than relying on monolithic, centrally supported, one-size-fits-all “enterpriseâ€platforms.
If you want more detail on anything in this article, or have any other questions, comments or contradictions, please post them below and I’ll get back to you as soon as I can.
Good article, agree with most things.
I would challenge the comment on Microsoft though… With dot net core and power shell they are doing a fantastic job of reinventing what had become a pretty stale platform at an impressive pace.
Having said that, they are mostly following patterns that Linux and OSS began, so you could argue whether it’s innovation or early follow.
Hey now, I never said anything about Microsoft, just Windows 😉 – Microsoft is doing just fine. .NET Core looks interesting, PowerShell is fine (though it’s probably a bit generous to call it an early follow), and Visual Studio Code is my current go-to text editor. But they’re all cross-platform, so not really points in favour of Windows.
The Windows comment may have been a little bit tongue-in-cheek, but it is a long way behind on Docker (and may never get to the same place given their ultra-lightweight base image packs in 600MB of stuff).
It’s not too hot on things like Node.js either, where many packages assume a full POSIX system, and the path length limit often bites you. NTFS seems to choke and take forever to do certain operations on projects with many thousands of tiny files too, which hits any interpreted language that relies on extensive dependency repositories.